
Python: Deep Learning Organic Chemistry
Introduction
Convolutional neural networks (CNNs) are a deep learning technology to use for classifying images. For this demonstration I used images from an introductory organic chemistry class. My problem was one of binary classification: could the CNN distinguish images with a structure called a benzene ring from images without a benzene ring? While I encountered challenges of working with a small dataset (with 205 images in each class), I did train the CNN to 73% accuracy of test data.
Methods
Technology used, source code, and image source
The software I used was Python, TensorFlow, and Keras. The source code is on GitHub along with all the training and test images. I obtained 410 images of molecular structures by taking photographs at various angles under many lighting conditions from the text Organic Chemistry, 6th Edition by John McMurry along with its accompanying student solutions manual. For each image, I cropped out all the text
Dataset description and classification problem
A detailed description of the organic chemistry involved in the training, test and validation datasets is beyond the scope of this article; however, a quick explanation about the data, as well as why the data have meaning in chemistry applications, should prove useful in understanding the CNN setup described here. An important part of studying chemical molecules involves breaking them into smaller substructures and analyzing each substructure individually. By understanding how each part works in the entire chemical structure, one can understand the properties of the compound as a whole. One important strucuture in organic chemistry is called a “benzene ring”. When the ring is found in a standalone configuration, with no other atoms surrounding it, it forms the compound benzene.
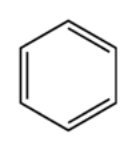
Figure 1: Benzene
Other parts of a molecule can be attached to these benzene rings, as shown in Figure 2:
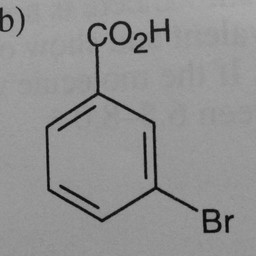 |
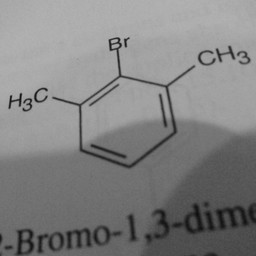 |
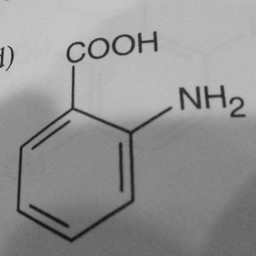 |
Other compounds do not contain these rings, as seen in the following molecules:
 |
 |
 |
The task for the CNN was binary classification to distinguish images of molecules with benzene rings from those without benzene rings.
Network architecture
I built the CNN in Keras with eight Conv2D and MaxPooling2D layers followed by two Dense layers. All layers except the final layer used a rectified linear unit (relu) activation function. The final layer used a sigmoid activation function because the problem was binary classification. The network layers were the following:
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 254, 254, 32) 320
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 127, 127, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 125, 125, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 62, 62, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 60, 60, 128) 73856
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 30, 30, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 28, 28, 128) 147584
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 14, 14, 128) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 25088) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 12845568
_________________________________________________________________
dense_2 (Dense) (None, 1) 513
=================================================================
Total params: 13,086,337
Trainable params: 13,086,337
Non-trainable params: 0 I used an 80%/20% split for the training/validation and test sets, respectively.
Results
For my first training run of the CNN, I trained for 10 epochs. At 5 epochs, however, a high validation accuracy was reached and the training accuracy started increasing rapidly. I interpreted this to mean that at 5 epochs I reached the optimum fit (from the maximum validation accuracy) before overfitting (from the rapidly increasing training accuracy). I retrained the model on a 5 epoch fit for the remainder of tests in this article. See Figure 4 for a plot of this training run:
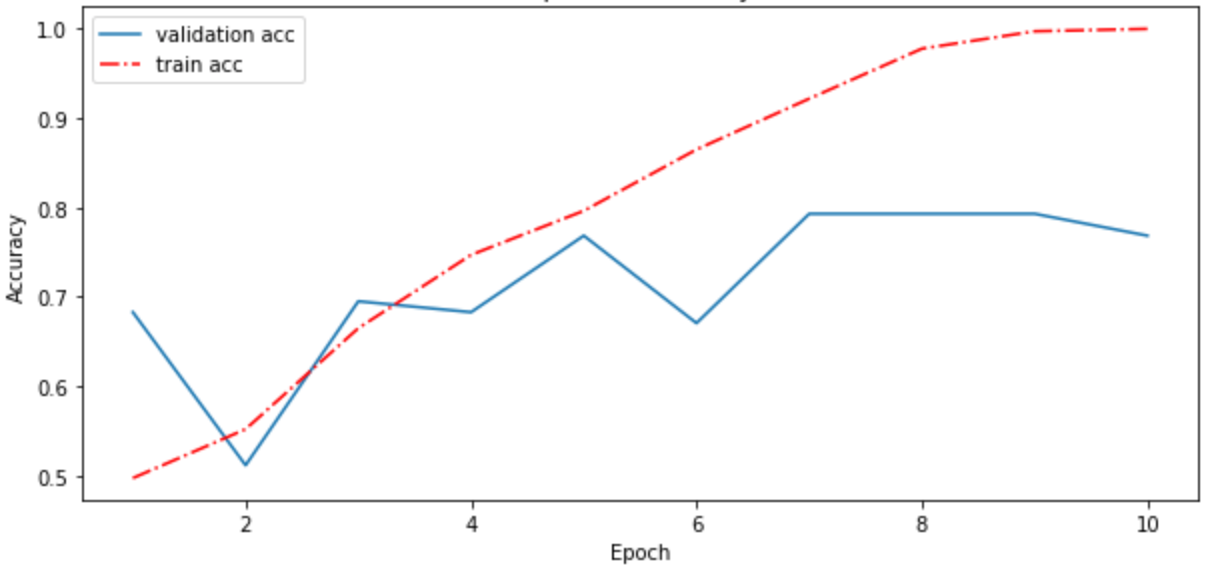
Figure 4: Accuracy vs Epoch
I took the output of the final sigmoid activation function to be y_prime. For every compound that had y_prime < 0.5, I classified the compound as having a benzene ring; for every compound that had y_prime >= 0.5, I classified the compound as not having a benezene ring. I then created a confusion matrix with the numbers of true negative (TN), false positive (FP), false negative (FN), and true negative (TN) occurrences.
| TP = 27 | FP = 8 |
| FN = 14 | TN = 33 |
This led to the following classifications as shown in the 82 test images as shown below. The false positive (FP) and (FN) labels denote the misclassification errors:
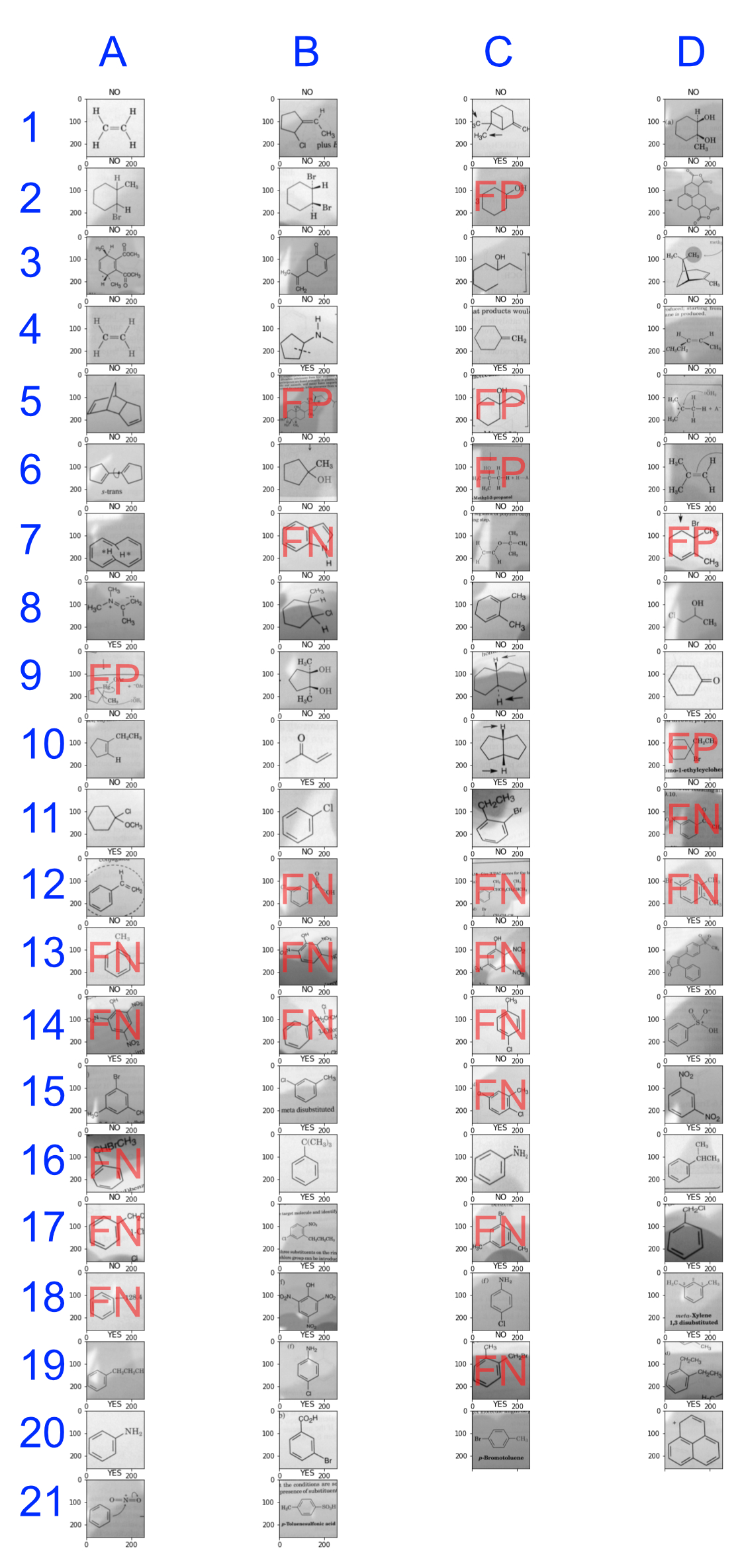
Figure 5: Classification results
Looking at the number of false negative misclassification results in these data leads me to believe that, if I set my threshold higher (0.6 instead of 0.5) I may be able to reduce the number of false negative classifications in a future experiment.
Discussion
When I initially ran this experiment, I used images from one organic chemistry text, which gave me only 410 images to use for training, validation and test data sets. That is not many images with which to train a CNN, and likely degraded its performance. Also, I ran out of memory on my GPU, which restricted the number and size of the layers. With more memory in a GPU I could add more Conv2D and Dense layers along with max pooling and drop out layers to prevent overfitting. That might improve performance as well. Perhaps using a pretrained CNN, for the convolutional layers would help. However, if I had to choose one thing to change, I suspect that gathering more images would probably be the best way to boost the CNN’s performance.
Conclusion
In this article, I described a CNN used to classify images that an undergraduate student would find in an introductory organic chemistry class. I found the limits of using a small dataset for training a CNN and described approaches on how to potentially boost the CNN’s performance in the future.
